
Este trabajo está motivado por la necesidad de hacer accesible con ejemplos prácticos una serie de tópicos que deberían formar parte obligatoria del plan de estudios de cualquier individuo que esté cursando una carrera universitaria en las ciencias y las ingenierías y que, desafortunadamente, no forma parte de las materias impartidas en muchas universidades en las cuales si se menciona algo del tema tal vez ello ocurra al final de los cursos introductorios de la materia de Estadística, y ello si queda tiempo para hablar del tema después de consumir la mayor parte del tiempo introduciendo al estudiante a la teoría de las probabilidades, la distribución hipergeométrica, la distribución binomial, la distribución normal, la distribución-t, el análisis de la varianza más lo que se alcance a ver después de tratar estos temas, lo cual deja poco tiempo para enseñarle al alumno esto que quizá debería ser lo primero que debería aprender por las vastas aplicaciones que esto tiene en diversas ramas del saber humano.
Empezaremos con una pregunta muy práctica:
Si no estamos cursando una Licenciatura en Matemáticas, ¿cuál sería la razón para dedicarle parte de nuestro tiempo a una materia que esencialmente es parte de una rama de las Matemáticas, la Estadística? ¿Cuál sería la razón por la cual deberíamos de estar motivados a aumentar aún más nuestra ya de por sí pesada carga de estudios con algo como el ajuste de datos a fórmulas?
Para responder a esta pregunta, veremos primero que el estudio de las técnicas matemáticas usadas para "ajustar" datos obtenidos experimentalmente a fórmulas prefijadas es la base indispensable para poder "avalar" nuestros modelos científicos teóricos con lo que se observa en la práctica todos los días en los laboratorios. Tomemos como ejemplo de ello la ley de la gravitación universal enunciada por vez primera por Sir Isaac Newton, la cual nos dice que dos cuerpos de masas M1 y M2 se atraen:

con una fuerza Fg que va en razón directa del producto de sus masas y en razón inversa del cuadrado de la distancia d que separa sus centros, lo cual está resumido en la siguiente fórmula:

Este concepto es tan elemental y tan importante, que incluso no se requiere llegar hasta la universidad para ser introducido a él, forma parte de los cursos básicos de ciencias naturales en las escuelas secundaria y preparatoria. Sin usar aún números, comparativamente hablando las consecuencias de ésta fórmula podemos resumirlas con los siguientes ejemplos:

En la esquina superior izquierda tenemos dos masas iguales cuyos centros geométricos están separados una distancia d, las cuales se están atrayendo con una fuerza F. En el segundo renglón y en la misma columna, ambas masas M son el doble del valor original, y por lo tanto la fuerza de atracción entre dichas masas será cuatro veces mayor, o sea 4F, ya que la fuerza de atracción es directamente proporcional al producto de las masas. Y en el tercer renglón sólo una de las masas es aumentada, a tres veces de su valor original, con lo cual la fuerza de atracción será tres veces mayor, aumentando a 3F. En la columna de la derecha, las masas son separadas a una distancia 2d que es el doble de la distancia original, y por lo tanto la fuerza de atracción entre ellas cae no a la mitad sino a la cuarta parte de su valor original porque la fuerza de atracción varía en razón inversa no de la distancia sino del cuadrado de la distancia que separa a las masas. Y en el tercer renglón en la columna de la derecha la fuerza de atracción entre las masas aumenta al cuádruple al ser acercadas las masas a la mitad de la distancia original. Y como podemos ver en la esquina inferior derecha, si ambas masas son aumentadas al doble y si la distancia que separa sus centros geométricos también es aumentada al doble, la fuerza de atracción entre las mismas no cambiará.
Hasta aquí hemos estado hablando en términos meramente cualitativos. Si queremos hablar en términos cuantitativos, usando números, entonces hay algo que necesitamos para poder utilizar la fórmula dada por Newton. Tenemos que determinar el valor de G, la constante de gravitación universal. En tanto que no podamos hacer tal cosa, no iremos muy lejos para poder usar dicha fórmula para predecir los movimientos de los planetas alrededor del Sol o el movimiento de la Luna alrededor de la Tierra. Y esta constante G no es algo que pueda ser determinado teóricamente, queramos o no tenemos que ir al laboratorio para llevar a cabo algún tipo de experimento con el cual podamos obtener el valor de G, el cual resulta ser:

Pero la determinación de esta constante marca apenas el inicio de nuestra labor. Podemos suponer que esta fórmula fue determinada bajo ciertas condiciones de laboratorio en las cuales había dos masas conocidas separadas por una distancia medida con la mayor precisión posible. El exponente 10-11 que aparece en el valor numérico de la constante G nos dice en cierta forma que el efecto a ser medido es extremadamente pequeño, lo cual es de esperarse, porque dos masas pequeñas del tamaño de una canica usadas para el experimento se atraerán con una fuerza muy débil apenas casi detectable. La existencia de una fuerza de atracción entre dos masas pequeñas se puede confirmar en un experimento de complejidad mediana, ello no presenta grandes desafíos. Pero el medir la constante G y no sólo comprobar que dos cuerpos se atraen representa serias dificultades. El primero en evaluar la constante G en el laboratorio fue Cavendish, quien usó un aparato que era esencialmente una balanza de torsión implementando el siguente esquema:

Aunque a primera vista se piense en la posibilidad de aumentar todas las masas usadas en el experimento para hacer más intenso el efecto atractivo que hay entre ellas, tal cosa no se puede llevar a cabo en las masas móviles (de color rojo) sin que se reviente el fino hilo del cual cuelgan dichas masas. Se pueden, sin embargo, aumentar las masas de color azul, y esto fue precisamente lo que hizo Cavendish. Obsérvese que no son sólo dos masas atrayéndose sino dos pares de masas atrayéndose, lo cual aumenta el efecto en la balanza de torsión. De cualquier modo, las enormes dificultades para obtener un valor numérico confiable de G bajo este experimento no contribuyen a aumentar nuestra confianza en el valor de G así obtenido.
De cualquier modo, un valor de G obtenido bajo estas condiciones y metido en la fórmula no nos garantiza que la fórmula va a trabajar como lo predijo Newton para otras condiciones que sean muy diferentes a las condiciones utilizadas en el laboratorio, en donde intervienen masas y distancias mucho mayores. Esta fórmula no es la única que nos puede dar una fuerza de atracción entre dos masas que disminuye a medida que aumenta la distancia de separación entre los centros geométricos de las masas. Podemos formular una ley que diga: "dos cuerpos se atraen en razón directa del producto de sus masas y en razón inversa de la distancia que los separa". Obsérvese la ausencia de la expresión "cuadrado de las distancia que los separa". Y podemos hacer que ambas fórmulas coincidan numéricamente para cierta distancia de separación, pero la variación en la fuerza de atracción dada por ambas fórmulas se irá haciendo cada vez más y más notorio conforme las masas van siendo acercadas o separadas más y más. Como ambas fórmulas, matemáticamente distintas, no pueden ser igualmente válidas para la descripción del mismo fenómeno, una de ellas tiene que ser desechada con la ayuda de datos obtenidos experimentalmente. Nuevamente, tenemos que ir al laboratorio. La confirmación de que la ley de Newton es válida la podemos obtener si podemos medir la fuerza de atracción para varias distancias haciendo una gráfica de los resultados. Para una variación inversamente proporcional al cuadrado de la distancia, la gráfica debe ser como sigue:

De un modo u otro, son experimentos de laboratorio los que nos ayudan a confirmar o desechar cualquier teoría como esta. Y en experimentos difíciles por su propia naturaleza, en los cuales se introduce un error aleatorio estadístico que nos puede introducir una variación experimental en cada lectura que tomemos, nos vemos casi obligados a recabar la mayor cantidad posible de datos para poder aumentar la confiabilidad de los resultados, en cuyo caso el problema será tratar de sacar alguna conclusión del cúmulo de datos recabados, porque no se puede esperar que todos o tal vez ninguno de los datos van a "caer" suavemente y en forma exacta sobre una curva continua. Esto nos obliga a tratar de encontrar de alguna manera la expresión matemática de una curva suave y continua, entre muchas otras posibles, que mejor se ajuste a los datos experimentales.
El caso del que hemos hablado se trata del caso típico en el que antes de llevar a cabo mediciones en el laboratorio ya existe un modelo teórico -una fórmula- en espera de ser confirmado experimentalmente por mediciones u observaciones llevadas a cabo después de haber sido obtenida la fórmula. Pero hay muchos otros casos en los cuales aunque los datos experimentales, pese a las fuentes inevitables de variación y de errores de medición, parecen seguir alguna ley que se pueda ajustar a un modelo teórico, tal fórmula no existe, ya sea porque aún no se ha encontrado o quizá porque es demasiado compleja para poder ser enunciada en unos cuantos renglones. En tales casos lo mejor que podemos hacer es llevar a cabo el ajuste de los datos obtenidos experimentalmente a una fórmula empírica, una fórmula seleccionada entre muchas por ser la que mejor acomoda los datos. El ejemplo más sonado de esto en la actualidad tiene que ver con el presunto calentamiento global de la Tierra, confirmado independientemente por varios datos recabados experimentalmente a lo largo de varias décadas en muchos sitios alrededor de la Tierra. Aún no tenemos una fórmula exacta y ni siquiera una fórmula empírica que nos permita vaticinar las temperaturas que tendrá la Tierra en años posteriores en caso de seguir las cosas como hasta ahora. Lo único que tenemos son gráficas en las cuales, globalmente hablando, se puede apreciar cierta tendencia hacia un incremento gradual en la temperatura, inferida por la tendencia de los datos (data trend), e inclusive algunos de estos datos son motivo de controversia, como los datos de las temperaturas registradas en Punta Arenas, Chile, entre 1888 y 2001:

Muchas veces, al llevar a cabo el graficado de los datos (el paso más importante previo a la selección del modelo matemático al cual trataremos de "ajustar" los datos), desde antes de tratar de llevar a cabo el ajuste de los datos a una fórmula podemos detectar la presencia de alguna anomalía en los mismos debida a una fuente inesperada de error que no tiene nada que ver con el error de naturaleza estadística, como lo muestra la siguiente gráfica de las temperaturas de los lagos de Detroit:

Obsérvese con detenimiento en esta gráfica que hay dos puntos que no fueron unidos con rectas por los investigadores para destacar la presencia de una anomalía grave en los datos. Se trata de los puntos que representan el final de 1999 y el principio del año 2000. Al empezar el año 2000, los datos muestran un "salto" desproporcionado en relación al historial previo de datos. Aunque podemos tratar de forzar todos los datos a que se agrupen bajo cierta tendencia predicha por una fórmula empírica, una anomalía como la que se observa en esta gráfica prácticamente nos pide a gritos una explicación antes de ser sepultada entre tal fórmula empírica. Un repaso de los datos reveló que, en efecto, el "brinco" desproporcionado tuvo que ver con un fenómeno que ya se preveía en esa época que iba a ocurrir con algunos sistemas computacionales no preparados para las consecuencias del cambio de dígitos en la fecha de 1999 a 2000, bautizado en ese entonces como el fenómeno Y2k (un acrónimo de la frase "Year 2000" en donde la k simboliza mil). El descubrimiento de este efecto dió pie a un intercambio de aclaraciones documentados en sitios como los siguientes:
http://www.climateaudit.org/?p=1854
http://www.climateaudit.org/?p=1868
Este intercambio de aclaraciones llevó a la misma agencia norteamericana espacial NASA a corregir sus propios datos tomando en cuenta el efecto Y2k, datos que ya corregidos aparecen en el siguiente sitio:
http://data.giss.nasa.gov/gistemp/graphs/Fig.D.txt
Los ejemplos que hemos visto han sido ejemplos en los cuales los datos experimentales pese a las variaciones en los mismos permiten el ajuste de los mismos a una fórmula matemática aproximada o permiten inclusive la detección de algún error en la recabación de los mismos. Pero hay muchas otras ocasiones en las cuales al llevar a cabo el graficado de los datos la presencia de alguna tendencia no resulta nada obvia, como lo muestra el siguiente ejemplo de datos recabados sobre la frecuencia de las manchas solares (lo cual tal vez tenga algún efecto sobre el calentamiento global de la Tierra):

En la gráfica de los datos se ha superimpuesto una línea roja que bajo un criterio matemático estadístico representa la línea de "mejor ajuste" a los datos. Pero en este caso esta línea no representa claramente un obvio descenso, inclusive la línea casi parece ser una línea horizontal. Si borramos la línea, los datos parecen tan dispersos que el haber escogido una línea recta para tratar de "agrupar" la tendencia de los datos parece más bien un acto de fé que de objetividad científica. Es posible que no haya razón alguna para esperar una variación estadísticamente significativa sobre la frecuencia de las manchas solares en el transcurso de varios siglos o inclusive de varios milenios, dada la enorme complejidad de los procesos nucleares que mantienen al Sol en constante actividad. Este último ejemplo demuestra las enormes dificultades que tiene que enfrentar cualquier investigador al tratar de analizar un conjunto de datos experimentales sobre los cuales no existe modelo teórico alguno.
En el ajuste de datos a fórmulas es de importancia vital tener siempre en mente la ley de causa y efecto. En el caso de la ley de la gravitación universal, enunciada mediante una fórmula exacta, si suponemos las masas de dos cuerpos como invariables, entonces una variación de la distancia que hay entre las masas tendrá un efecto directo sobre la fuerza de atracción gravitatoria que hay entre ellas. Una serie de datos experimentales puestos sobre una gráfica nos confirmará esto. Y aún en casos en los que no hay un modelo exacto, podemos (o mejor dicho, tenemos que) suponer una relación causa-efecto para que un modelo entre dos variables pueda tener algún sentido. Tal sería el caso al llevar a cabo las mediciones de las estaturas entre alumnos de diversos grados de una escuela primaria. En este caso, las estaturas promedio de los alumnos correspondientes a cada grado será diferente, irá aumentando conforme vaya aumentando el grado escolar, por el simple hecho de que los alumnos a esa edad van aumentando cada año de estatura. En pocas palabras, entre mayor sea el grado escolar, mayor será la estatura promedio de los alumnos que esperamos encontrar en un grupo. Esta es una relación causa-efecto. En contraste, si queremos encontrar una relación directa entre la temperatura ambiente de una ciudad para cierto día del año y la cantidad de animales domésticos que los habitantes tienen en sus casas, lo más probable es que no encontraremos relación alguna y saldremos con las manos vacías, porque no hay razón alguna para esperar que la cantidad promedio de mascotas en cada hogar (causa) puede tener alguna influencia sobre la temperatura ambiente (efecto), y si la tiene, tal efecto sería matemáticamente despreciable por su pequeñez.
Los casos que hemos visto involucran situaciones basadas en fenómenos naturales para los cuales podemos llevar a cabo mediciones en el laboratorio o fuera del laboratorio usando algo tan simple como un termómetro o como un telescopio de aficionados. Pero hay muchos otros casos en los cuales no es necesario llevar a cabo mediciones, porque más que obtener datos en el laboratorio lo que se necesita es tener un modelo matemático que nos permita hacer una proyección o un vaticinio con los datos que ya se tienen a la mano, como los datos obtenidos en un censo o en una encuesta. Un ejemplo de ello es el crecimiento esperado de la población anual de México. El censo nacional de población es el que se encarga de estar obteniendo cifras sobre la población de México, de manera tal que para poder tratar de hacer un vaticinio sobre el crecimiento esperado de la población en años futuros todo lo que tenemos que hacer es ir al Instituto Nacional de Estadística, Geografía e Informática (INEGI) para obtener los resultados de los censos anteriores. Se dá por hecho que los datos numéricos en dichos censos no son exactos, no hay razón para esperar tal cosa, dada la enorme cantidad de variables que tienen que enfrentar los trabajadores que deben llevar a cabo los censos y la situación cambiante día a día que puede afectar la "realidad" del censo. Aún suponiendo que los censos se pudieran llevar a cabo en forma exacta, nos quedaría otro problema. Si graficamos los índices de población de cada 5 años (por ejemplo), no habría problema alguno en hacer predicciones futuras en base a los datos del pasado si los datos al ser graficados cayeran todos en una "línea recta". El problema es que al ser graficados casi nunca caen en una línea recta, por lo general se agrupan en torno a lo que parece ser una curva. Aquí podemos tratar de "ajustar" los datos a una de varias fórmulas y utilizar la que mejor se aproxime a todos los datos que ya se tienen, para lo cual necesitamos de un criterio matemático-estadístico que sea lo menos subjetivo posible. Y es precisamente para esto para lo cual requerimos de los principios que serán tratados aquí.
En el ajuste de datos a fórmulas, existen casos en los cuales no es necesario entrar en cálculos matemáticos detallados por la sencilla razón de que para tales casos se han obtenido ya fórmulas que únicamente requieren el cálculo de cosas tan sencillas como la media aritmética (frecuentemente designada como µ, la letra griega mu, equivalente de la letra latina "m", por lo de media aritmética) de los datos y la desviación estándard σ (la letra griega sigma, el equivalente de la letra latina "s", por lo de "standard") de los mismos. Nos estamos refiriendo al ajuste de los datos a una curva Gaussiana. Un ajuste de este tipo se aplica a situaciones en las cuales en lugar de tener alguna variable dependiente Y cuyos valores dependan de los valores que pueda tomar una variable independiente X sobre la que tal vez se pueda ejercer algún control tenemos un conjunto de datos en los cuales lo importante es la frecuencia con la cual los datos que se recaban estén situados dentro de ciertos rangos. Un ejemplo de ello serían las calificaciones en cierta materia de un grupo numeroso de 160 estudiantes cuyas calificaciones muestren una distribución como la siguiente:

Por la forma en la cual están presentados los datos, tenemos que hacer una ligera modificación en nuestros cálculos para poder obtener la media aritmética de los mismos, usando como el valor representativo de cada intervalo el valor medio entre el mínimo y el máximo de cada intervalo. Así, el valor representativo del intervalo entre una calificación de 4.5 y 5.0 será 4.75, el valor representativo del intervalo entre 5.0 y 5.5 será 5.25, y así sucesivamente. A cada uno de estos valores representativos de cada intervalo tenemos que darle el peso "justo" que le corresponde en el cálculo de la media aritmética multiplicándolo por la frecuencia con la cual ocurre. Así, el valor 4.75 será multiplicado por 4 puesto que esa es la frecuencia con la cual ocurre, y el valor 5.25 será multiplicado por 7 puesto que esa es la frecuencia con la cual ocurre, y así sucesivamente. De este modo, la media aritmética de la población de los 150 estudiantes será:
Habiendo obtenido la media aritmética X, el siguiente paso sería obtener la dispersión de dichos datos con respecto a la media aritmética, a través de un cálculo como la varianza σ² en la cual promediamos la suma de los cuadrados de las diferencias di de cada dato con respecto a la media aritmética para obtener la varianza σ² de la población de datos:
con lo cual podemos obtener la desviación estándard σ de la población de datos (conocida también como la raíz cuadrada media de las desviaciones -distancias- de los datos a la media aritmética) con la simple operación de tomar la raíz cuadrada de la varianza:
Cabe aclarar que la desviación estándard σ evaluada para una muestra tomada al azar de entre una población tiene una definición un poco diferente a la desviación estándard σ evaluada sobre todos los datos del total de la población. La desviación estándard σ de la muestra de una población se obtiene reemplazando el término N en el denominador por N-1, porque al decir de los "puristas" el valor así obtenido es una mejor estimación de la desviación estándard de la población de la cual fue tomada la muestra. Sin embargo, para valores suficientemente grandes de una muestra (N mayor que 30), prácticamente no hay diferencia alguna entre ambas estimaciones de σ. De cualquier modo, cuando se desea obtener una "mejor estimación", siempre se puede obtener multiplicando la desviación estándard que hemos definido por √N/N-1 . Es importante tener en mente que σ es una medida hasta cierto punto arbitraria de una dispersión de datos, es algo que nosotros mismos hemos definido, y el que utilicemos N-1 en vez de N en el denominador en realidad no es un absoluto. Sin embargo, es una convención universalmente aceptada, quizá entre otras cosas (además de las razones teóricas esgrimidas por los puristas) por el hecho de que para calcular una dispersión de datos se requieren por lo menos dos datos, lo cual es reconocido implícitamente por el uso de N-1 en el denominador ya que de esta manera no es posible darle a N un valor de uno sin caer en una división por cero; la definición que utiliza a N-1 elimina del panorama cualquier interpretación posible de σ con un solo dato. Y la otra razón de peso que tiene que ver más con las razones argumentadas por los puristas es que el uso de N-1 en el denominador tiene que ver con algo que se llama los grados de libertad en el análisis de la varianza conocido como ANOVA (Análisis of Variance) que se utiliza en el diseño de experimentos (aunque esto ya es salirnos un poco del tema que estamos discutiendo en esta obra).
En la estadística descriptiva, la cual se lleva a cabo teniendo todos los valores de una población de datos y no tomando una muestra de dicha población, lo más relevante de la gráfica de las frecuencias relativas de los datos o histograma es el "área bajo la curva" y no tanto la fórmula de la curva que deba pasar por la "altura" de cada grupo de datos, usándose la curva para encontrar la probabilidad matemática de tener a un grupo estudiantes entre cierto rango de calificaciones, por ejemplo entre 7.5 y 9.0, una probabilidad cuyo valor matemático siempre está situado entre cero y la unidad. Esto es lo que tradicionalmente se enseña en los libros de texto.
Sin embargo, antes de aplicar las tablas estadísticas para llevar a cabo algún análisis probabilístico del "área bajo la curva", es de interés saber qué tan bien se ajustan los datos a una curva continua que se pueda trazar conectando las alturas del histograma. La fórmula que mejor describe a un conjunto de datos como los que se han mostrado en el ejemplo es la que dá origen a la curva Gaussiana. A continuación, para la siguiente fórmula "Gaussiana":

tenemos la gráfica de la curva continua trazada por dicha fórmula:

Como puede verse, la curva ciertamente tiene la forma de una campana, de lo cual deriva uno de los nombres con los cuales es conocida.
Se puede demostrar, recurriendo a un criterio matemático conocido como el método de los mínimos cuadrados, que una fórmula general que modela una curva Gaussiana a un conjunto dado de datos con la apariencia de una "campana" es la siguiente:

Y resulta que µ es precisamente la media aritmética de la población de datos designada también como X, mientras que σ² es la varianza presentada por la población de datos. Esto signica que, para modelar una curva a un conjunto de datos como el que hemos estado manejando en el ejemplo, basta con calcular la media aritmética y la varianza de los datos, y meter estos datos directamente a la fórmula Gaussiana, con lo cual tendremos la curva de "mejor ajuste" (bajo el criterio de los mínimos cuadrados) a los datos. La evaluación del parámetro A no representa problema alguno, ya que la curva debe llegar (más no sobrepasar) hasta una altura de 34 (el número de estudiantes que representa la mayor frecuencia con respecto a los otros rangos de calificaciones), de tal modo que la fórmula de la curva ajustada a los datos del ejemplo es la siguiente:

La gráfica de esta curva Gaussiana, superimpuesta sobre la gráfica de barras que contiene los datos discretos a partir de los cuales fue generada, es la siguiente:

Podemos ver que el ajuste es razonablemente bueno, considerando el hecho de que en la vida real los datos experimentales u observados nunca se ajustan exactamente a una curva Gaussiana ideal.
Una cosa con la cual tenemos que lidiar desde un principio y la cual casi nunca es suficientemente aclarada y explicada bien en los salones de clase es el hecho de que la fórmula Gaussiana general permite no solo valores positivos de X sino inclusive permite también valores negativos, los cuales carecen de interpretación en el mundo real en casos como el que acabamos de ver (en un sistema de calificaciones de estudiantes como el que estamos suponiendo, cualquier calificación solo puede variar de cero como calificación mínima a diez como calificación máxima). En principio, X puede variar desde X=-∞ hasta X=+∞. En muchos casos esto no representa problema alguno, ya que la curva se aproxima rápidamente a cero antes de que X descienda debajo de cero tomando valores negativos, como ocurre en nuestro ejemplo en donde la media aritmética está lo suficientemente alejada de X=0 y la dispersión de los datos es lo suficientemente pequeña para considerar a los valores negativos de X como irrelevantes aunque la fórmula lo permita. Pero en casos en los cuales la media aritmética X está demasiado cercana a X=0 y los datos manifiestan una dispersión grande, cabe siempre la posibilidad de que un extremo de la curva termine cayendo "del otro lado" en la zona para la cual X toma valores negativos. Si esto llega a suceder, esto podría obligarnos inclusive a abandonar el modelo Gaussiano y buscar otras alternativas que ciertamente serán más desagradables de manejar desde el punto de vista matemático.
Se ha proporcionado un procedimiento para poder obtener la fórmula de una curva que pueda conectar las alturas de cada barra de un histograma de datos que muestre la forma de la "campana", pero es importante aclarar que los puntos individuales de la curva carecen de significado real; lo cual equivale a que afirmar que un punto como X=7.8 para el cual el valor de Y es igual a 28.595 es algo que no nos debe significar absolutamente nada, ya que es la región bajo la curva lo que tiene sentido, ya que la curva fue generada a partir de barras de histograma que van cambiando de un intervalo a otro. Sin embargo, lo que hemos hecho aquí está justificado para fines comparativos porque antes de aplicar nuestras nociones de estadística a un conjunto de datos usando la distribución Gaussiana queremos cerciorarnos sobre si realmente los datos que vamos a analizar tienen la forma de una campana, porque si los datos parecen seguir una tendencia linear siempre ascendente o si en lugar de una campana tenemos dos campanas (esto último ocurre cuando se van acumulando datos que provienen de dos fuentes diferentes), mal haríamos en tratar de forzar tales datos sobre una distribución Gaussiana. Es importante agregar también que la curva que hemos visto no es la curva Gaussiana que se estudia en los textos de estadística, ya que para ello tenemos que normalizar la fórmula de modo tal que no solo la media aritmética sea desplazada hacia la izquierda en el diagrama para que tenga un valor de cero siendo simétrica hacia ambos lados con respecto a X=o, sino que además el área bajo la curva tenga como valor la unidad; esto con el objeto de darle a la curva una interpretación probabilística en su aplicación no a la estadística descriptiva sino a la estadística inferencial en la cual de una muestra tomada al azar tratamos de averiguar el comportamiento de los datos de una población general. De este proceso de normalización deriva el nombre de dicha curva como curva normal.
Antes de tratar de invertir tiempo y esfuerzo en ajustar datos empíricos a una fórmula, antes de hacer cualquier cálculo aritmético, es importante hacer cuanto antes una gráfica de los datos, ya que esto es lo primero que habrá de guiarnos en la selección del modelo matemático que habremos de utilizar para el modelaje. En el caso de distribuciones de frecuencias como las que hemos estado viendo, las cuales se representan por medio de histogramas, si al hacer una gráfica de los datos obtenemos algo como lo siguiente:
entonces si bien podemos "forzar" los datos a que entren dentro de alguna fórmula modelada sobre una variable independiente continua cuyo trazo se "ajuste" a las alturas de las barras de los histogramas, obteniendo en este último ejemplo un ajuste como el siguiente (este ajuste se llevó a cabo simplemente sumando las expresiones para dos curvas Gaussianas con medias aritméticas distintas, modificando individualmente las varianzas y las amplitudes de cada curva al tanteo):

este ajuste será un ajuste sin sentido, ya que una gráfica como esta, conocida como gráfica bimodal, la cual tiene dos "topes" máximos, nos está diciendo que en vez de tener una población de datos con el mismo origen lo que tenemos es dos poblaciones de datos con orígenes distintos, datos que llegaron revueltos en un solo "paquete" a manos del analista. Es entonces cuando el analista prácticamente está obligado a ir al "campo" para ver cómo y de dónde fueron recabados los datos. Es posible que los datos representen las longitudes de ciertas vigas que fueron producidas por dos máquinas diferentes. También es posible que estos datos se hayan originado en un experimento en donde se estaba probando el efecto de un nuevo tipo de fertilizante en el rendimiento de unos cultivos y que el fertilizante estaba siendo suministrado a parcelas experimentales por dos personas diferentes en dos lugares diferentes, en cuyo caso hay algo que está produciendo una diferencia significativa en el rendimiento del fertilizante además del efecto que pueda tener el fertilizante en sí, ya sea que ambas personas hayan estado suministrando cantidades diferentes del mismo fertilizante, o que las características de diferentes terrenos hayan causado una alteración en la distribución Gaussiana del rendimiento de cada tipo de fertilizante.
En el caso de la curva continua con "doble joroba" mostrada arriba, esta curva fue trazada por la siguiente fórmula obtenida al tanteo sumando dos curvas Gaussianas y fijando el "tope" de cada curva para hacer coincidir de modo aproximado -manipulando la media aritmética µ en cada término- los topes con cada una de las dos barras máximas, modificando también la varianza σ en cada término para "abrir" o "cerrar" el ancho de cada curva ajustándolo a voluntad:

A continuación tenemos las gráficas separadas individualmente (no sumadas) de cada una de las curvas Gaussianas que aparecen en la fórmula, mostrando una distribución probable de los datos de las dos poblaciones distintas de las cuales procedieron los datos revueltos.

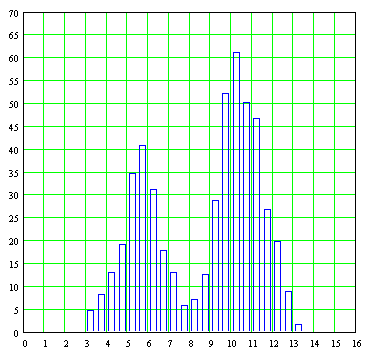
En este ejemplo, resultó fácil con solo ver el histograma -la gráfica de barras de los datos- la presencia de dos curvas Gaussianas en lugar de una sola, gracias a que las medias aritméticas de cada curva (5.7 y 10.4) están separadas casi por un margen de dos a uno. Pero no siempre tendremos tanta suerte, y habrá casos en los que las medias aritméticas estarán tan cercanas la una a la otra que le será algo difícil al analista decidir si considera todos los datos como uno solo o si trata de encontrar dos curvas distintas, como ocurriría con una gráfica cuya curva uniendo las alturas de las barras tuviera el siguiente aspecto:
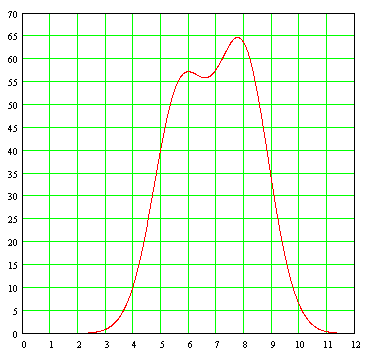
Es en casos como estos en los cuales el analista tiene que echar mano de todo su ingenio y toda su experiencia para decidir si trata de encontrar dos grupos discernibles de datos en el conjunto de datos que tiene a la mano, o si no vale la pena buscar la presencia de dos poblaciones distintas revueltas en una sola, optando por llevar a cabo el modelaje en base a una sola fórmula Gaussiana.
El descubrir la influencia de factores desconocidos que puedan afectar el rendimiento de algo como un fertilizante es precisamente uno de los objetivos primarios del diseño de experimentos. En el diseño de experimentos no estamos interesados en llevar a cabo un modelaje de los datos a una fórmula, eso viene después cuando se ha determinado de manera unívoca cuántos y cuáles son los factores que pueden alterar el rendimiento o la respuesta de algo. Una vez que se superado esta etapa, entonces podemos recabar datos para llevar a cabo el ajuste de datos a una fórmula. En el caso de una distribución bimodal, en vez de tratar de ajustar una fórmula para describir todos los datos con una sola distribución como la que hemos visto, es mucho más provechoso tratar de separar los datos provenientes de las dos distintas poblaciones que están provocando la "doble joroba de camello"; hecho esto podemos analizar dos conjuntos de datos por separado con la seguridad de que para cada conjunto de datos obtendremos una distribución Gaussiana con una sola "joroba". Puede verse con esto que el modelaje de datos a fórmulas es un ciclo continuo de experimentación, análisis e interpretación de los resultados, seguido de un nuevo ciclo de experimentación y de análisis e interpretación de nuevos resultados con el fin de ir mejorando algún proceso o poder ir describiendo mejor los datos que están siendo recabados en algún laboratorio o en el campo. El modelaje de datos a fórmulas va de la mano con los procedimientos para la recabación de los mismos.
PROBLEMA: Experimentalmente, se encuentra en el laboratorio que el punto de ebullición para unos compuestos orgánicos conocidos como los alcanos (con fórmula química CnH2n+2) tiene los siguientes valores en grados Centígrados:
Metano (1 átomo de carbono): -161.7
Etano (2 átomos de carbono): -88.6
Propano (3 átomos de carbono) : -42.1
Butano (4 átomos de carbono): -0.5
Pentano (5 átomos de carbono): 36.1
Hexano (6 átomos de carbono): 68.7
Heptano (7 átomos de carbono): 98.4
Octano (8 átomos de carbono): 125.7
Nonano (9 átomos de carbono): 150.8
Decano (10 átomos de carbono): 174.0
Hacer una gráfica de los datos.¿Muestra alguna tendencia la temperatura de ebullición de estos compuestos orgánicos de acuerdo con la cantidad de átomos de carbono que posee cada compuesto?
La gráfica de los datos discretos es la siguiente:

En la gráfica podemos observar que los datos parecen acomodarse a una curva continua sin saltos bruscos, obedeciendo la relación causa-efecto, lo cual nos sugiere que detrás de estos datos hay una ley natural en espera de ser descubierta por nosotros. Puesto que los datos no parecen seguir una línea recta, la relación que hay entre ellos no es una relación linear, es una relación no-linear, y no esperamos que la fórmula matemática que esté detrás de esta curva sea la de una línea recta. En ausencia de un modelo teórico que nos permita tener la fórmula exacta, la gráfica originada por este conjunto de datos es una muestra excelente de los lugares en donde podemos tratar de ajustar los datos a una fórmula empírica que, entre mejor se ajuste a los datos, mejor nos sugerirá la naturaleza de las leyes naturales operando detrás de este fenómeno.

Aunque a primera vista se piense en la posibilidad de aumentar todas las masas usadas en el experimento para hacer más intenso el efecto atractivo que hay entre ellas, tal cosa no se puede llevar a cabo en las masas móviles (de color rojo) sin que se reviente el fino hilo del cual cuelgan dichas masas. Se pueden, sin embargo, aumentar las masas de color azul, y esto fue precisamente lo que hizo Cavendish. Obsérvese que no son sólo dos masas atrayéndose sino dos pares de masas atrayéndose, lo cual aumenta el efecto en la balanza de torsión. De cualquier modo, las enormes dificultades para obtener un valor numérico confiable de G bajo este experimento no contribuyen a aumentar nuestra confianza en el valor de G así obtenido.
De cualquier modo, un valor de G obtenido bajo estas condiciones y metido en la fórmula no nos garantiza que la fórmula va a trabajar como lo predijo Newton para otras condiciones que sean muy diferentes a las condiciones utilizadas en el laboratorio, en donde intervienen masas y distancias mucho mayores. Esta fórmula no es la única que nos puede dar una fuerza de atracción entre dos masas que disminuye a medida que aumenta la distancia de separación entre los centros geométricos de las masas. Podemos formular una ley que diga: "dos cuerpos se atraen en razón directa del producto de sus masas y en razón inversa de la distancia que los separa". Obsérvese la ausencia de la expresión "cuadrado de las distancia que los separa". Y podemos hacer que ambas fórmulas coincidan numéricamente para cierta distancia de separación, pero la variación en la fuerza de atracción dada por ambas fórmulas se irá haciendo cada vez más y más notorio conforme las masas van siendo acercadas o separadas más y más. Como ambas fórmulas, matemáticamente distintas, no pueden ser igualmente válidas para la descripción del mismo fenómeno, una de ellas tiene que ser desechada con la ayuda de datos obtenidos experimentalmente. Nuevamente, tenemos que ir al laboratorio. La confirmación de que la ley de Newton es válida la podemos obtener si podemos medir la fuerza de atracción para varias distancias haciendo una gráfica de los resultados. Para una variación inversamente proporcional al cuadrado de la distancia, la gráfica debe ser como sigue:

De un modo u otro, son experimentos de laboratorio los que nos ayudan a confirmar o desechar cualquier teoría como esta. Y en experimentos difíciles por su propia naturaleza, en los cuales se introduce un error aleatorio estadístico que nos puede introducir una variación experimental en cada lectura que tomemos, nos vemos casi obligados a recabar la mayor cantidad posible de datos para poder aumentar la confiabilidad de los resultados, en cuyo caso el problema será tratar de sacar alguna conclusión del cúmulo de datos recabados, porque no se puede esperar que todos o tal vez ninguno de los datos van a "caer" suavemente y en forma exacta sobre una curva continua. Esto nos obliga a tratar de encontrar de alguna manera la expresión matemática de una curva suave y continua, entre muchas otras posibles, que mejor se ajuste a los datos experimentales.
El caso del que hemos hablado se trata del caso típico en el que antes de llevar a cabo mediciones en el laboratorio ya existe un modelo teórico -una fórmula- en espera de ser confirmado experimentalmente por mediciones u observaciones llevadas a cabo después de haber sido obtenida la fórmula. Pero hay muchos otros casos en los cuales aunque los datos experimentales, pese a las fuentes inevitables de variación y de errores de medición, parecen seguir alguna ley que se pueda ajustar a un modelo teórico, tal fórmula no existe, ya sea porque aún no se ha encontrado o quizá porque es demasiado compleja para poder ser enunciada en unos cuantos renglones. En tales casos lo mejor que podemos hacer es llevar a cabo el ajuste de los datos obtenidos experimentalmente a una fórmula empírica, una fórmula seleccionada entre muchas por ser la que mejor acomoda los datos. El ejemplo más sonado de esto en la actualidad tiene que ver con el presunto calentamiento global de la Tierra, confirmado independientemente por varios datos recabados experimentalmente a lo largo de varias décadas en muchos sitios alrededor de la Tierra. Aún no tenemos una fórmula exacta y ni siquiera una fórmula empírica que nos permita vaticinar las temperaturas que tendrá la Tierra en años posteriores en caso de seguir las cosas como hasta ahora. Lo único que tenemos son gráficas en las cuales, globalmente hablando, se puede apreciar cierta tendencia hacia un incremento gradual en la temperatura, inferida por la tendencia de los datos (data trend), e inclusive algunos de estos datos son motivo de controversia, como los datos de las temperaturas registradas en Punta Arenas, Chile, entre 1888 y 2001:

De acuerdo con la gráfica de estos datos sobre los cuales se ha ajustado una línea recta de color rojo que, matemáticamente hablando, representa la tendencia de los datos promediados con el tiempo, la temperatura en esa parte del mundo no ha ido aumentando a lo largo de más de un siglo, sino que por el contrario ha ido disminuyendo en un promedio acumulado de unos 0.6 grados Centígrados, contraviniendo las mediciones que se han estado llevando a cabo en otras partes del mundo. Aún no sabemos exactamente la razón por la cual lo que ocurre allí es diferente a lo que se observa en otras partes del mundo. Posiblemente hay interacciones con las temperaturas del mar, con las condiciones climáticas en esa región del planeta, o inclusive hasta con la rotación de la Tierra, que están influyendo para causar una caída en lugar de una subida en las temperaturas observadas en Punta Arenas. De cualquier modo, pese a las altas y bajas de los datos, con tales datos es posible obtener la línea recta de color rojo -superimpuesta sobre los datos- que matemáticamente hablando se "ajusta" mejor que otras rectas al promedio acumulado móvil de los datos. De mantenerse la tendencia, esta línea recta nos permite estimar, entre las altas y bajas que vayan ocurriendo en los datos en los años posteriores, las temperaturas promedio que habrá a corto plazo en Punta Arenas en los años venideros. Sobre estos datos, la recta de mejor ajuste (best fit) representa una fórmula completamente empírica para la cual no existe hasta la fecha ningún modelo teórico que la apoye. Y así como esta fórmula hay muchísimas en las cuales se trata de simplificar con algún modelo matemático algo que se está observando o midiendo.
Muchas veces, al llevar a cabo el graficado de los datos (el paso más importante previo a la selección del modelo matemático al cual trataremos de "ajustar" los datos), desde antes de tratar de llevar a cabo el ajuste de los datos a una fórmula podemos detectar la presencia de alguna anomalía en los mismos debida a una fuente inesperada de error que no tiene nada que ver con el error de naturaleza estadística, como lo muestra la siguiente gráfica de las temperaturas de los lagos de Detroit:

Obsérvese con detenimiento en esta gráfica que hay dos puntos que no fueron unidos con rectas por los investigadores para destacar la presencia de una anomalía grave en los datos. Se trata de los puntos que representan el final de 1999 y el principio del año 2000. Al empezar el año 2000, los datos muestran un "salto" desproporcionado en relación al historial previo de datos. Aunque podemos tratar de forzar todos los datos a que se agrupen bajo cierta tendencia predicha por una fórmula empírica, una anomalía como la que se observa en esta gráfica prácticamente nos pide a gritos una explicación antes de ser sepultada entre tal fórmula empírica. Un repaso de los datos reveló que, en efecto, el "brinco" desproporcionado tuvo que ver con un fenómeno que ya se preveía en esa época que iba a ocurrir con algunos sistemas computacionales no preparados para las consecuencias del cambio de dígitos en la fecha de 1999 a 2000, bautizado en ese entonces como el fenómeno Y2k (un acrónimo de la frase "Year 2000" en donde la k simboliza mil). El descubrimiento de este efecto dió pie a un intercambio de aclaraciones documentados en sitios como los siguientes:
http://www.climateaudit.org/?p=1854
http://www.climateaudit.org/?p=1868
Este intercambio de aclaraciones llevó a la misma agencia norteamericana espacial NASA a corregir sus propios datos tomando en cuenta el efecto Y2k, datos que ya corregidos aparecen en el siguiente sitio:
http://data.giss.nasa.gov/gistemp/graphs/Fig.D.txt
Los ejemplos que hemos visto han sido ejemplos en los cuales los datos experimentales pese a las variaciones en los mismos permiten el ajuste de los mismos a una fórmula matemática aproximada o permiten inclusive la detección de algún error en la recabación de los mismos. Pero hay muchas otras ocasiones en las cuales al llevar a cabo el graficado de los datos la presencia de alguna tendencia no resulta nada obvia, como lo muestra el siguiente ejemplo de datos recabados sobre la frecuencia de las manchas solares (lo cual tal vez tenga algún efecto sobre el calentamiento global de la Tierra):

En la gráfica de los datos se ha superimpuesto una línea roja que bajo un criterio matemático estadístico representa la línea de "mejor ajuste" a los datos. Pero en este caso esta línea no representa claramente un obvio descenso, inclusive la línea casi parece ser una línea horizontal. Si borramos la línea, los datos parecen tan dispersos que el haber escogido una línea recta para tratar de "agrupar" la tendencia de los datos parece más bien un acto de fé que de objetividad científica. Es posible que no haya razón alguna para esperar una variación estadísticamente significativa sobre la frecuencia de las manchas solares en el transcurso de varios siglos o inclusive de varios milenios, dada la enorme complejidad de los procesos nucleares que mantienen al Sol en constante actividad. Este último ejemplo demuestra las enormes dificultades que tiene que enfrentar cualquier investigador al tratar de analizar un conjunto de datos experimentales sobre los cuales no existe modelo teórico alguno.
En el ajuste de datos a fórmulas es de importancia vital tener siempre en mente la ley de causa y efecto. En el caso de la ley de la gravitación universal, enunciada mediante una fórmula exacta, si suponemos las masas de dos cuerpos como invariables, entonces una variación de la distancia que hay entre las masas tendrá un efecto directo sobre la fuerza de atracción gravitatoria que hay entre ellas. Una serie de datos experimentales puestos sobre una gráfica nos confirmará esto. Y aún en casos en los que no hay un modelo exacto, podemos (o mejor dicho, tenemos que) suponer una relación causa-efecto para que un modelo entre dos variables pueda tener algún sentido. Tal sería el caso al llevar a cabo las mediciones de las estaturas entre alumnos de diversos grados de una escuela primaria. En este caso, las estaturas promedio de los alumnos correspondientes a cada grado será diferente, irá aumentando conforme vaya aumentando el grado escolar, por el simple hecho de que los alumnos a esa edad van aumentando cada año de estatura. En pocas palabras, entre mayor sea el grado escolar, mayor será la estatura promedio de los alumnos que esperamos encontrar en un grupo. Esta es una relación causa-efecto. En contraste, si queremos encontrar una relación directa entre la temperatura ambiente de una ciudad para cierto día del año y la cantidad de animales domésticos que los habitantes tienen en sus casas, lo más probable es que no encontraremos relación alguna y saldremos con las manos vacías, porque no hay razón alguna para esperar que la cantidad promedio de mascotas en cada hogar (causa) puede tener alguna influencia sobre la temperatura ambiente (efecto), y si la tiene, tal efecto sería matemáticamente despreciable por su pequeñez.
Los casos que hemos visto involucran situaciones basadas en fenómenos naturales para los cuales podemos llevar a cabo mediciones en el laboratorio o fuera del laboratorio usando algo tan simple como un termómetro o como un telescopio de aficionados. Pero hay muchos otros casos en los cuales no es necesario llevar a cabo mediciones, porque más que obtener datos en el laboratorio lo que se necesita es tener un modelo matemático que nos permita hacer una proyección o un vaticinio con los datos que ya se tienen a la mano, como los datos obtenidos en un censo o en una encuesta. Un ejemplo de ello es el crecimiento esperado de la población anual de México. El censo nacional de población es el que se encarga de estar obteniendo cifras sobre la población de México, de manera tal que para poder tratar de hacer un vaticinio sobre el crecimiento esperado de la población en años futuros todo lo que tenemos que hacer es ir al Instituto Nacional de Estadística, Geografía e Informática (INEGI) para obtener los resultados de los censos anteriores. Se dá por hecho que los datos numéricos en dichos censos no son exactos, no hay razón para esperar tal cosa, dada la enorme cantidad de variables que tienen que enfrentar los trabajadores que deben llevar a cabo los censos y la situación cambiante día a día que puede afectar la "realidad" del censo. Aún suponiendo que los censos se pudieran llevar a cabo en forma exacta, nos quedaría otro problema. Si graficamos los índices de población de cada 5 años (por ejemplo), no habría problema alguno en hacer predicciones futuras en base a los datos del pasado si los datos al ser graficados cayeran todos en una "línea recta". El problema es que al ser graficados casi nunca caen en una línea recta, por lo general se agrupan en torno a lo que parece ser una curva. Aquí podemos tratar de "ajustar" los datos a una de varias fórmulas y utilizar la que mejor se aproxime a todos los datos que ya se tienen, para lo cual necesitamos de un criterio matemático-estadístico que sea lo menos subjetivo posible. Y es precisamente para esto para lo cual requerimos de los principios que serán tratados aquí.
En el ajuste de datos a fórmulas, existen casos en los cuales no es necesario entrar en cálculos matemáticos detallados por la sencilla razón de que para tales casos se han obtenido ya fórmulas que únicamente requieren el cálculo de cosas tan sencillas como la media aritmética (frecuentemente designada como µ, la letra griega mu, equivalente de la letra latina "m", por lo de media aritmética) de los datos y la desviación estándard σ (la letra griega sigma, el equivalente de la letra latina "s", por lo de "standard") de los mismos. Nos estamos refiriendo al ajuste de los datos a una curva Gaussiana. Un ajuste de este tipo se aplica a situaciones en las cuales en lugar de tener alguna variable dependiente Y cuyos valores dependan de los valores que pueda tomar una variable independiente X sobre la que tal vez se pueda ejercer algún control tenemos un conjunto de datos en los cuales lo importante es la frecuencia con la cual los datos que se recaban estén situados dentro de ciertos rangos. Un ejemplo de ello serían las calificaciones en cierta materia de un grupo numeroso de 160 estudiantes cuyas calificaciones muestren una distribución como la siguiente:
Entre 4.5 y 5.0: 4 estudiantesEste tipo de distribuciones, cuando son graficadas, estadísticamente muestran cierta tendencia de llegar a alcanzar un punto máximo en una curva que se asemeja a una campana. El primer cálculo que podemos efectuar sobre tales datos es el promedio aritmético o media aritmética definida como:
Entre 5.0 y 5.5: 7 estudiantes
Entre 5.5 y 6.0: 11 estudiantes
Entre 6.0 y 6.5: 16 estudiantes
Entre 6.5 y 7.0: 29 estudiantes
Entre 7.0 y 7.5: 34 estudiantes
Entre 7.5 y 8.0: 26 estudiantes
Entre 8.0 y 8.5: 15 estudiantes
Entre 8.5 y 9.0: 11 estudiantes
Entre 9.0 y 9.5: 5 estudiantes
Entre 9.5 y 10.0: 2 estudiantes

Por la forma en la cual están presentados los datos, tenemos que hacer una ligera modificación en nuestros cálculos para poder obtener la media aritmética de los mismos, usando como el valor representativo de cada intervalo el valor medio entre el mínimo y el máximo de cada intervalo. Así, el valor representativo del intervalo entre una calificación de 4.5 y 5.0 será 4.75, el valor representativo del intervalo entre 5.0 y 5.5 será 5.25, y así sucesivamente. A cada uno de estos valores representativos de cada intervalo tenemos que darle el peso "justo" que le corresponde en el cálculo de la media aritmética multiplicándolo por la frecuencia con la cual ocurre. Así, el valor 4.75 será multiplicado por 4 puesto que esa es la frecuencia con la cual ocurre, y el valor 5.25 será multiplicado por 7 puesto que esa es la frecuencia con la cual ocurre, y así sucesivamente. De este modo, la media aritmética de la población de los 150 estudiantes será:
X = [(4)(4.75) + (7)(5.25) + (11)(5.75) + ... (9.75)(2)]/160
X = 7.178
X = 7.178
Habiendo obtenido la media aritmética X, el siguiente paso sería obtener la dispersión de dichos datos con respecto a la media aritmética, a través de un cálculo como la varianza σ² en la cual promediamos la suma de los cuadrados de las diferencias di de cada dato con respecto a la media aritmética para obtener la varianza σ² de la población de datos:
Σd² = 4∙(4.75-7.178)² + 7(5.25-7.178 )² + ... + 2∙(2-7.178)²
Σd² = 178.923
σ² = Σd²/N = 1.118
Σd² = 178.923
σ² = Σd²/N = 1.118
con lo cual podemos obtener la desviación estándard σ de la población de datos (conocida también como la raíz cuadrada media de las desviaciones -distancias- de los datos a la media aritmética) con la simple operación de tomar la raíz cuadrada de la varianza:
σ = √1.118 = 1.057
Cabe aclarar que la desviación estándard σ evaluada para una muestra tomada al azar de entre una población tiene una definición un poco diferente a la desviación estándard σ evaluada sobre todos los datos del total de la población. La desviación estándard σ de la muestra de una población se obtiene reemplazando el término N en el denominador por N-1, porque al decir de los "puristas" el valor así obtenido es una mejor estimación de la desviación estándard de la población de la cual fue tomada la muestra. Sin embargo, para valores suficientemente grandes de una muestra (N mayor que 30), prácticamente no hay diferencia alguna entre ambas estimaciones de σ. De cualquier modo, cuando se desea obtener una "mejor estimación", siempre se puede obtener multiplicando la desviación estándard que hemos definido por √N/N-1 . Es importante tener en mente que σ es una medida hasta cierto punto arbitraria de una dispersión de datos, es algo que nosotros mismos hemos definido, y el que utilicemos N-1 en vez de N en el denominador en realidad no es un absoluto. Sin embargo, es una convención universalmente aceptada, quizá entre otras cosas (además de las razones teóricas esgrimidas por los puristas) por el hecho de que para calcular una dispersión de datos se requieren por lo menos dos datos, lo cual es reconocido implícitamente por el uso de N-1 en el denominador ya que de esta manera no es posible darle a N un valor de uno sin caer en una división por cero; la definición que utiliza a N-1 elimina del panorama cualquier interpretación posible de σ con un solo dato. Y la otra razón de peso que tiene que ver más con las razones argumentadas por los puristas es que el uso de N-1 en el denominador tiene que ver con algo que se llama los grados de libertad en el análisis de la varianza conocido como ANOVA (Análisis of Variance) que se utiliza en el diseño de experimentos (aunque esto ya es salirnos un poco del tema que estamos discutiendo en esta obra).
En la estadística descriptiva, la cual se lleva a cabo teniendo todos los valores de una población de datos y no tomando una muestra de dicha población, lo más relevante de la gráfica de las frecuencias relativas de los datos o histograma es el "área bajo la curva" y no tanto la fórmula de la curva que deba pasar por la "altura" de cada grupo de datos, usándose la curva para encontrar la probabilidad matemática de tener a un grupo estudiantes entre cierto rango de calificaciones, por ejemplo entre 7.5 y 9.0, una probabilidad cuyo valor matemático siempre está situado entre cero y la unidad. Esto es lo que tradicionalmente se enseña en los libros de texto.
Sin embargo, antes de aplicar las tablas estadísticas para llevar a cabo algún análisis probabilístico del "área bajo la curva", es de interés saber qué tan bien se ajustan los datos a una curva continua que se pueda trazar conectando las alturas del histograma. La fórmula que mejor describe a un conjunto de datos como los que se han mostrado en el ejemplo es la que dá origen a la curva Gaussiana. A continuación, para la siguiente fórmula "Gaussiana":

tenemos la gráfica de la curva continua trazada por dicha fórmula:

Como puede verse, la curva ciertamente tiene la forma de una campana, de lo cual deriva uno de los nombres con los cuales es conocida.
Se puede demostrar, recurriendo a un criterio matemático conocido como el método de los mínimos cuadrados, que una fórmula general que modela una curva Gaussiana a un conjunto dado de datos con la apariencia de una "campana" es la siguiente:

Y resulta que µ es precisamente la media aritmética de la población de datos designada también como X, mientras que σ² es la varianza presentada por la población de datos. Esto signica que, para modelar una curva a un conjunto de datos como el que hemos estado manejando en el ejemplo, basta con calcular la media aritmética y la varianza de los datos, y meter estos datos directamente a la fórmula Gaussiana, con lo cual tendremos la curva de "mejor ajuste" (bajo el criterio de los mínimos cuadrados) a los datos. La evaluación del parámetro A no representa problema alguno, ya que la curva debe llegar (más no sobrepasar) hasta una altura de 34 (el número de estudiantes que representa la mayor frecuencia con respecto a los otros rangos de calificaciones), de tal modo que la fórmula de la curva ajustada a los datos del ejemplo es la siguiente:

La gráfica de esta curva Gaussiana, superimpuesta sobre la gráfica de barras que contiene los datos discretos a partir de los cuales fue generada, es la siguiente:

Podemos ver que el ajuste es razonablemente bueno, considerando el hecho de que en la vida real los datos experimentales u observados nunca se ajustan exactamente a una curva Gaussiana ideal.
Una cosa con la cual tenemos que lidiar desde un principio y la cual casi nunca es suficientemente aclarada y explicada bien en los salones de clase es el hecho de que la fórmula Gaussiana general permite no solo valores positivos de X sino inclusive permite también valores negativos, los cuales carecen de interpretación en el mundo real en casos como el que acabamos de ver (en un sistema de calificaciones de estudiantes como el que estamos suponiendo, cualquier calificación solo puede variar de cero como calificación mínima a diez como calificación máxima). En principio, X puede variar desde X=-∞ hasta X=+∞. En muchos casos esto no representa problema alguno, ya que la curva se aproxima rápidamente a cero antes de que X descienda debajo de cero tomando valores negativos, como ocurre en nuestro ejemplo en donde la media aritmética está lo suficientemente alejada de X=0 y la dispersión de los datos es lo suficientemente pequeña para considerar a los valores negativos de X como irrelevantes aunque la fórmula lo permita. Pero en casos en los cuales la media aritmética X está demasiado cercana a X=0 y los datos manifiestan una dispersión grande, cabe siempre la posibilidad de que un extremo de la curva termine cayendo "del otro lado" en la zona para la cual X toma valores negativos. Si esto llega a suceder, esto podría obligarnos inclusive a abandonar el modelo Gaussiano y buscar otras alternativas que ciertamente serán más desagradables de manejar desde el punto de vista matemático.
Se ha proporcionado un procedimiento para poder obtener la fórmula de una curva que pueda conectar las alturas de cada barra de un histograma de datos que muestre la forma de la "campana", pero es importante aclarar que los puntos individuales de la curva carecen de significado real; lo cual equivale a que afirmar que un punto como X=7.8 para el cual el valor de Y es igual a 28.595 es algo que no nos debe significar absolutamente nada, ya que es la región bajo la curva lo que tiene sentido, ya que la curva fue generada a partir de barras de histograma que van cambiando de un intervalo a otro. Sin embargo, lo que hemos hecho aquí está justificado para fines comparativos porque antes de aplicar nuestras nociones de estadística a un conjunto de datos usando la distribución Gaussiana queremos cerciorarnos sobre si realmente los datos que vamos a analizar tienen la forma de una campana, porque si los datos parecen seguir una tendencia linear siempre ascendente o si en lugar de una campana tenemos dos campanas (esto último ocurre cuando se van acumulando datos que provienen de dos fuentes diferentes), mal haríamos en tratar de forzar tales datos sobre una distribución Gaussiana. Es importante agregar también que la curva que hemos visto no es la curva Gaussiana que se estudia en los textos de estadística, ya que para ello tenemos que normalizar la fórmula de modo tal que no solo la media aritmética sea desplazada hacia la izquierda en el diagrama para que tenga un valor de cero siendo simétrica hacia ambos lados con respecto a X=o, sino que además el área bajo la curva tenga como valor la unidad; esto con el objeto de darle a la curva una interpretación probabilística en su aplicación no a la estadística descriptiva sino a la estadística inferencial en la cual de una muestra tomada al azar tratamos de averiguar el comportamiento de los datos de una población general. De este proceso de normalización deriva el nombre de dicha curva como curva normal.
Antes de tratar de invertir tiempo y esfuerzo en ajustar datos empíricos a una fórmula, antes de hacer cualquier cálculo aritmético, es importante hacer cuanto antes una gráfica de los datos, ya que esto es lo primero que habrá de guiarnos en la selección del modelo matemático que habremos de utilizar para el modelaje. En el caso de distribuciones de frecuencias como las que hemos estado viendo, las cuales se representan por medio de histogramas, si al hacer una gráfica de los datos obtenemos algo como lo siguiente:

entonces si bien podemos "forzar" los datos a que entren dentro de alguna fórmula modelada sobre una variable independiente continua cuyo trazo se "ajuste" a las alturas de las barras de los histogramas, obteniendo en este último ejemplo un ajuste como el siguiente (este ajuste se llevó a cabo simplemente sumando las expresiones para dos curvas Gaussianas con medias aritméticas distintas, modificando individualmente las varianzas y las amplitudes de cada curva al tanteo):

este ajuste será un ajuste sin sentido, ya que una gráfica como esta, conocida como gráfica bimodal, la cual tiene dos "topes" máximos, nos está diciendo que en vez de tener una población de datos con el mismo origen lo que tenemos es dos poblaciones de datos con orígenes distintos, datos que llegaron revueltos en un solo "paquete" a manos del analista. Es entonces cuando el analista prácticamente está obligado a ir al "campo" para ver cómo y de dónde fueron recabados los datos. Es posible que los datos representen las longitudes de ciertas vigas que fueron producidas por dos máquinas diferentes. También es posible que estos datos se hayan originado en un experimento en donde se estaba probando el efecto de un nuevo tipo de fertilizante en el rendimiento de unos cultivos y que el fertilizante estaba siendo suministrado a parcelas experimentales por dos personas diferentes en dos lugares diferentes, en cuyo caso hay algo que está produciendo una diferencia significativa en el rendimiento del fertilizante además del efecto que pueda tener el fertilizante en sí, ya sea que ambas personas hayan estado suministrando cantidades diferentes del mismo fertilizante, o que las características de diferentes terrenos hayan causado una alteración en la distribución Gaussiana del rendimiento de cada tipo de fertilizante.
En el caso de la curva continua con "doble joroba" mostrada arriba, esta curva fue trazada por la siguiente fórmula obtenida al tanteo sumando dos curvas Gaussianas y fijando el "tope" de cada curva para hacer coincidir de modo aproximado -manipulando la media aritmética µ en cada término- los topes con cada una de las dos barras máximas, modificando también la varianza σ en cada término para "abrir" o "cerrar" el ancho de cada curva ajustándolo a voluntad:

A continuación tenemos las gráficas separadas individualmente (no sumadas) de cada una de las curvas Gaussianas que aparecen en la fórmula, mostrando una distribución probable de los datos de las dos poblaciones distintas de las cuales procedieron los datos revueltos.

En este ejemplo, resultó fácil con solo ver el histograma -la gráfica de barras de los datos- la presencia de dos curvas Gaussianas en lugar de una sola, gracias a que las medias aritméticas de cada curva (5.7 y 10.4) están separadas casi por un margen de dos a uno. Pero no siempre tendremos tanta suerte, y habrá casos en los que las medias aritméticas estarán tan cercanas la una a la otra que le será algo difícil al analista decidir si considera todos los datos como uno solo o si trata de encontrar dos curvas distintas, como ocurriría con una gráfica cuya curva uniendo las alturas de las barras tuviera el siguiente aspecto:

Es en casos como estos en los cuales el analista tiene que echar mano de todo su ingenio y toda su experiencia para decidir si trata de encontrar dos grupos discernibles de datos en el conjunto de datos que tiene a la mano, o si no vale la pena buscar la presencia de dos poblaciones distintas revueltas en una sola, optando por llevar a cabo el modelaje en base a una sola fórmula Gaussiana.
El descubrir la influencia de factores desconocidos que puedan afectar el rendimiento de algo como un fertilizante es precisamente uno de los objetivos primarios del diseño de experimentos. En el diseño de experimentos no estamos interesados en llevar a cabo un modelaje de los datos a una fórmula, eso viene después cuando se ha determinado de manera unívoca cuántos y cuáles son los factores que pueden alterar el rendimiento o la respuesta de algo. Una vez que se superado esta etapa, entonces podemos recabar datos para llevar a cabo el ajuste de datos a una fórmula. En el caso de una distribución bimodal, en vez de tratar de ajustar una fórmula para describir todos los datos con una sola distribución como la que hemos visto, es mucho más provechoso tratar de separar los datos provenientes de las dos distintas poblaciones que están provocando la "doble joroba de camello"; hecho esto podemos analizar dos conjuntos de datos por separado con la seguridad de que para cada conjunto de datos obtendremos una distribución Gaussiana con una sola "joroba". Puede verse con esto que el modelaje de datos a fórmulas es un ciclo continuo de experimentación, análisis e interpretación de los resultados, seguido de un nuevo ciclo de experimentación y de análisis e interpretación de nuevos resultados con el fin de ir mejorando algún proceso o poder ir describiendo mejor los datos que están siendo recabados en algún laboratorio o en el campo. El modelaje de datos a fórmulas va de la mano con los procedimientos para la recabación de los mismos.
PROBLEMA: Experimentalmente, se encuentra en el laboratorio que el punto de ebullición para unos compuestos orgánicos conocidos como los alcanos (con fórmula química CnH2n+2) tiene los siguientes valores en grados Centígrados:
Metano (1 átomo de carbono): -161.7
Etano (2 átomos de carbono): -88.6
Propano (3 átomos de carbono) : -42.1
Butano (4 átomos de carbono): -0.5
Pentano (5 átomos de carbono): 36.1
Hexano (6 átomos de carbono): 68.7
Heptano (7 átomos de carbono): 98.4
Octano (8 átomos de carbono): 125.7
Nonano (9 átomos de carbono): 150.8
Decano (10 átomos de carbono): 174.0
Hacer una gráfica de los datos.¿Muestra alguna tendencia la temperatura de ebullición de estos compuestos orgánicos de acuerdo con la cantidad de átomos de carbono que posee cada compuesto?
La gráfica de los datos discretos es la siguiente:

En la gráfica podemos observar que los datos parecen acomodarse a una curva continua sin saltos bruscos, obedeciendo la relación causa-efecto, lo cual nos sugiere que detrás de estos datos hay una ley natural en espera de ser descubierta por nosotros. Puesto que los datos no parecen seguir una línea recta, la relación que hay entre ellos no es una relación linear, es una relación no-linear, y no esperamos que la fórmula matemática que esté detrás de esta curva sea la de una línea recta. En ausencia de un modelo teórico que nos permita tener la fórmula exacta, la gráfica originada por este conjunto de datos es una muestra excelente de los lugares en donde podemos tratar de ajustar los datos a una fórmula empírica que, entre mejor se ajuste a los datos, mejor nos sugerirá la naturaleza de las leyes naturales operando detrás de este fenómeno.
PROBLEMA: Dada la siguiente distribución de los diámetros de las cabezas de unos remaches (expresados en pulgadas) fabricados por cierta compañía y la frecuencia f con la que ocurren:

representativa de un total de 250 mediciones, ajustar una curva Gaussiana a estos datos. Asimismo, hacer el trazo de una gráfica de barras de los datos superimponiendo la curva Gaussiana en la misma gráfica.
Para obtener la curva Gaussiana, el primer paso consiste en obtener la media aritmética de los datos:

Por la forma en la cual están presentados los datos, tenemos que hacer una ligera modificación en nuestros cálculos para poder obtener la media aritmética de los mismos, usando como el valor representativo de cada intervalo el valor medio entre el mínimo y el máximo de cada intervalo. Así, el valor representativo del intervalo entre .7247 y .7249 será .7248, el valor representativo del intervalo entre .7250 y .7252 será .7251, y así sucesivamente. A cada uno de estos valores representativos de cada intervalo tenemos que darle el peso "justo" que le corresponde en el cálculo de la media aritmética multiplicándolo por la frecuencia con la cual ocurre. Así, el valor .7248 será multiplicado por 2 puesto que esa es la frecuencia con la cual ocurre, y el valor .7251 será multiplicado por 6 puesto que esa es la frecuencia con la cual ocurre, y así sucesivamente. De este modo, la media aritmética de la población de 250 datos será:
Tras esto obtenemos la desviación estándard σ calculando primero la varianza σ2, usando también aquí en nuestros cálculos los valores representativos de cada intervalo y la frecuencia con la cual ocurre cada uno de dichos valores:
Con esto tenemos todo lo que necesitamos para producir la curva Gaussiana ajustada a los datos. La altura de la curva es seleccionada para coincidir con la barra (representativa del rango de datos) que tenga también la mayor altura, la cual viene siendo el rango de diámetros comprendido entre .7262 y .7264 pulgadas con una "altura" de 68 unidades. De este modo, la gráfica, utilizando una "altura" para la curva Gaussiana de 68 unidades, es la siguiente:

El ajuste de la curva Gaussiana a los datos no parece ser tan "ideal" como hubiéramos querido. Esto tiene que ver con algo más fundamental que el hecho de que la media aritmética X de los datos (.72642 pulgadas) no coincide exactamente con el punto representativo del intervalo de valores (.7263) en el cual ocurre la mayor frecuencia de las 68 observaciones (y se enfatiza aquí como algo de la mayor importancia que en la vida real es muy rara la vez en la cual el máximo de la curva calculada coincide con el valor aritmético más probable que viene siendo el promedio aritmético), y mucho menos con el hecho de que la gráfica de barras ha sido trazada sin que cada barra se extienda hasta tocarse con sus barras vecinas. Si observamos bien la distribución de los datos, podemos apreciar que los datos de la distribución de barras están más cargados hacia la derecha que hacia la izquierda. La curva Gaussiana ideal que hemos venido manejando es una curva perfectamente simétrica, con la misma cantidad de datos u observaciones distribuídos hacia la derecha de su eje vertical de simetría que hacia la izquierda. Esta asimetría es conocida como sesgo (skew) o ladeo precisamente porque los datos originales están cargados más de un lado que del otro; esto es precisamente lo que hace que el "máximo" de la distribución de barras en la gráfica no coincida con la media aritmética de los datos. Y aunque existe un teorema en Estadística conocido como el Teorema del Límite Central (Central Limit Theorem) que nos dice que la suma de un gran número de variables aleatorias independientes se irán distribuyendo en forma normal (Gaussiana) conforme aumenta la cantidad de datos u observaciones, el tomar más y más lecturas no necesariamente hará que los datos que se están ajustando a una curva se vuelvan más simétricos, ello no ocurrirá si hay razones de fondo por las cuales hay más datos cargados hacia un lado que hacia el otro. Esta es una situación que la curva Gaussiana ideal no está preparada para manejar, y si queremos ajustar en forma precisa una curva a datos en los cuales esperaríamos un comportamiento Gaussiano ideal entonces tenemos que modificar la curva Gaussiana volviendo la fórmula más compleja, recurriendo a algún truco tal como el multiplicar la amplitud de la curva por algún factor que haga que su descenso no sea tan "suave" ya sea hacia la derecha o hacia la izquierda. Desafortunadamente, el recurso a este tipo de trucos muchas veces carece de justificaciones teóricas que expliquen la modificación a la curva modelada, son simplemente un recurso para obtener un ajuste más preciso. Es aquí cuando el experimentador o el analista de los datos tiene que decidir si el objetivo que está procurando realmente justifica el recurrir a este tipo de trucos que, aunque logran su propósito, no ayudan a mejorar nuestra comprensión sobre lo que está sucediendo detrás de un cúmulo de datos.

representativa de un total de 250 mediciones, ajustar una curva Gaussiana a estos datos. Asimismo, hacer el trazo de una gráfica de barras de los datos superimponiendo la curva Gaussiana en la misma gráfica.
Para obtener la curva Gaussiana, el primer paso consiste en obtener la media aritmética de los datos:

Por la forma en la cual están presentados los datos, tenemos que hacer una ligera modificación en nuestros cálculos para poder obtener la media aritmética de los mismos, usando como el valor representativo de cada intervalo el valor medio entre el mínimo y el máximo de cada intervalo. Así, el valor representativo del intervalo entre .7247 y .7249 será .7248, el valor representativo del intervalo entre .7250 y .7252 será .7251, y así sucesivamente. A cada uno de estos valores representativos de cada intervalo tenemos que darle el peso "justo" que le corresponde en el cálculo de la media aritmética multiplicándolo por la frecuencia con la cual ocurre. Así, el valor .7248 será multiplicado por 2 puesto que esa es la frecuencia con la cual ocurre, y el valor .7251 será multiplicado por 6 puesto que esa es la frecuencia con la cual ocurre, y así sucesivamente. De este modo, la media aritmética de la población de 250 datos será:
X = [2∙(.7248) + 6∙(.7251) + 8∙(.7254) + ... + 4∙(.7278) + 1∙(.7281)]/250
X = 181.604/250
X = .72642 pulgadas
X = 181.604/250
X = .72642 pulgadas
Tras esto obtenemos la desviación estándard σ calculando primero la varianza σ2, usando también aquí en nuestros cálculos los valores representativos de cada intervalo y la frecuencia con la cual ocurre cada uno de dichos valores:
Σd² = 2∙(.7248-.72646)² + 6(.7251-.72642)² + ... + 1∙(.7281-.72642)²
Σd² = 0.000082926
σ² = Σd²/N = 0.00008292/250 = 0.000000331704
σ = .00057594 pulgadas
Σd² = 0.000082926
σ² = Σd²/N = 0.00008292/250 = 0.000000331704
σ = .00057594 pulgadas
Con esto tenemos todo lo que necesitamos para producir la curva Gaussiana ajustada a los datos. La altura de la curva es seleccionada para coincidir con la barra (representativa del rango de datos) que tenga también la mayor altura, la cual viene siendo el rango de diámetros comprendido entre .7262 y .7264 pulgadas con una "altura" de 68 unidades. De este modo, la gráfica, utilizando una "altura" para la curva Gaussiana de 68 unidades, es la siguiente:

El ajuste de la curva Gaussiana a los datos no parece ser tan "ideal" como hubiéramos querido. Esto tiene que ver con algo más fundamental que el hecho de que la media aritmética X de los datos (.72642 pulgadas) no coincide exactamente con el punto representativo del intervalo de valores (.7263) en el cual ocurre la mayor frecuencia de las 68 observaciones (y se enfatiza aquí como algo de la mayor importancia que en la vida real es muy rara la vez en la cual el máximo de la curva calculada coincide con el valor aritmético más probable que viene siendo el promedio aritmético), y mucho menos con el hecho de que la gráfica de barras ha sido trazada sin que cada barra se extienda hasta tocarse con sus barras vecinas. Si observamos bien la distribución de los datos, podemos apreciar que los datos de la distribución de barras están más cargados hacia la derecha que hacia la izquierda. La curva Gaussiana ideal que hemos venido manejando es una curva perfectamente simétrica, con la misma cantidad de datos u observaciones distribuídos hacia la derecha de su eje vertical de simetría que hacia la izquierda. Esta asimetría es conocida como sesgo (skew) o ladeo precisamente porque los datos originales están cargados más de un lado que del otro; esto es precisamente lo que hace que el "máximo" de la distribución de barras en la gráfica no coincida con la media aritmética de los datos. Y aunque existe un teorema en Estadística conocido como el Teorema del Límite Central (Central Limit Theorem) que nos dice que la suma de un gran número de variables aleatorias independientes se irán distribuyendo en forma normal (Gaussiana) conforme aumenta la cantidad de datos u observaciones, el tomar más y más lecturas no necesariamente hará que los datos que se están ajustando a una curva se vuelvan más simétricos, ello no ocurrirá si hay razones de fondo por las cuales hay más datos cargados hacia un lado que hacia el otro. Esta es una situación que la curva Gaussiana ideal no está preparada para manejar, y si queremos ajustar en forma precisa una curva a datos en los cuales esperaríamos un comportamiento Gaussiano ideal entonces tenemos que modificar la curva Gaussiana volviendo la fórmula más compleja, recurriendo a algún truco tal como el multiplicar la amplitud de la curva por algún factor que haga que su descenso no sea tan "suave" ya sea hacia la derecha o hacia la izquierda. Desafortunadamente, el recurso a este tipo de trucos muchas veces carece de justificaciones teóricas que expliquen la modificación a la curva modelada, son simplemente un recurso para obtener un ajuste más preciso. Es aquí cuando el experimentador o el analista de los datos tiene que decidir si el objetivo que está procurando realmente justifica el recurrir a este tipo de trucos que, aunque logran su propósito, no ayudan a mejorar nuestra comprensión sobre lo que está sucediendo detrás de un cúmulo de datos.
Hay experimentos en los cuales aunque resulta tentador obtener de inmediato una fórmula de "mejor ajuste" a una serie de datos, tal fórmula servirá de muy poco para obtener una conclusión o descubrimiento verdaderamente importante que puede ser extraído con un poco de astucia en el estudio de los datos acumulados. Un ejemplo de ello es el siguiente problema (problema 31) tomado del capítulo 27 (El Campo Eléctrico) del libro "Física para Estudiantes de Ciencias e Ingeniería" de David Halliday y Robert Resnick:
PROBLEMA: En uno de sus primeros experimentos (1911) Millikan observó que, entre otras cargas, aparecían en diferentes momentos las siguientes, medidas en una gota determinada:
6.563•10-19 coulombs¿Qué valor de la carga elemental puede deducirse de estos datos?
8.204•10-19 coulombs
11.50•10-19 coulombs
13.13•10-19 coulombs
16.48•10-19 coulombs
18.08•10-19 coulombs
19.71•10-19 coulombs
22.89•10-19 coulombs
26.13•10-19 coulombs
Acomodando los datos en orden creciente de magnitud, podemos hacer una gráfica de los mismos que resulta ser la siguiente (esta gráfica así como otras puestas en esta obra puede ser vista con mayor claridad o inclusive en varios casos ampliada con el simple recurso de ampliar la imagen):

Es importante destacar que en esta gráfica no hay una variable independiente (cuyo valor quedaría puesto en el eje horizontal) ni una variable dependiente (cuyo valor sería puesto en el eje vertical), ya que en el eje horizontal simplemente se ha asignado un número ordinal diferente a cada uno de los valores experimentales anotados; de este modo el primer dato (1) tiene un valor de 6.563•10-19, el segundo dato (2) tiene un valor de 8.204•10-19, y así sucesivamente.
Podemos, si queremos, obtener una línea recta de "mejor ajuste" para estos datos trazada a mano. Pero esto pierde por completo la perspectiva del experimento. Una gráfica mucho más útil que la gráfica de puntos arriba mostrada es la siguiente gráfica de los datos conocida como gráfica de escalera o gráfica de paso:

Inspeccionando detenidamente la gráfica de estos datos, podemos darnos cuenta de que hay "escalones" cuya altura parece ser la misma de un dato al siguiente. La diferencia entre las observaciones 1 y 2, por ejemplo, parece ser la misma que la diferencia entre las observaciones 6 y 7. Y aquellos "saltos" en donde no lo es, la altura parece ser el doble de la altura de los otros escalones. Si la altura de un escalón al siguiente no tuviera esta similitud con ninguna de las observaciones restantes, podríamos concluír que las diferencias son completamente aleatorias. Pero esto no es lo que está ocurriendo, y los escalones parecen tener alturas iguales o doblemente iguales. Estos datos nos están revelando algo importante, que la carga eléctrica está cuantizada; la carga eléctrica reportada aquí no varía en tantos de 0.7, 1.4 ó 2.5, sino en múltiplos enteros de uno o dos tantos. Los datos nos están confirmando la existencia del electrón, la carga eléctrica más pequeña que ya no es posible subdividir por medios físicos o químicos a nuestro alcance. Entre los datos en los cuales el "salto" de un escalón a otro es el doble del que hay en otros escalones, podemos concluír que hay datos "ausentes" y que, con una cantidad adicional de experimentos, deberá ser posible encontrar valores experimentales entre esos saltos "dobles" que, puestos en la gráfica, nos deberán producir una escalera con escalones de la misma altura que podríamos llamar "básica". A manera de ejemplo, entre el valor reportado de 11.50•10-19 coulombs y 8.204•10-19 coulombs debe de haber un valor intermedio de unos 9.582•10-19 coulombs que con una recabación adicional de datos en el laboratorio debería ser posible detectar tarde o temprano.
Podemos estimar la magnitud de este cuanto de carga eléctrica que hoy conocemos como el electrón obteniendo primero las diferencias entre los datos que representan un salto unitario obteniendo el promedio de los mismos, y tras esto las diferencias entre los datos que representan un salto "doble" obteniendo también el promedio de los mismos y dividiendo el resultado de este último entre dos, sumando y promediando los dos conjuntos de valores para obtener así un resultado final:
Conjunto 1 (salto unitario):
8.204•10-19 - 6.563•10-19 = 1.641•10-19Conjunto 2 (salto doble):
13.13•10-19 - 11.50•10-19 = 1.63•10-19
18.08•10-19 - 16.48•10-19 = 1.6•10-19
19.71•10-19 - 18.08•10-19 = 1.63•10-19
11.50•10-19 - 8.204•10-19 = 3.296•10-19El promedio del primer conjunto de datos es:
16.48•10-19 - 13.13•10-19 = 3.35•10-19
22.89•10-19 - 19.71•10-19 = 3.18•10-19
26.13•10-19 - 22.89•10-19 = 3.24•10-19
(1.641•10-19 + 1.63•10-19 + 1.6•10-19 + 1.63•10-19) /4 = 1.625•10-19 coulombs
Y el promedio del segundo conjunto de datos es:
(3.376•10-19 + 3.35•10-19 + 3.18•10-19 + 3.24•10-19) /4 = 3.2655•10-19
que dividido entre dos resulta ser:
3.2655•10-19 /2 = 1.633•10-19 coulombs
Como hay tantos datos (4 datos) en el primer conjunto como en el segundo conjunto, podemos darle el mismo "peso aritmético" a cada uno de los promedios obtenidos, sumando el primer promedio al segundo promedio y dividiendo el resultado entre dos (de no haber sido así, de haber tenido ambos conjuntos una cantidad diferente de observaciones, tendríamos que darle un "factor de peso" aritmético a cada conjunto para darle a cada contribución de acuerdo a su importancia relativa):
(1.625•10-19 + 1.633•10-19) /2 = 1.63•10-19 coulombs
Como colofón a este problema, se agrega que experimentos llevados a cabo posteriormente con mayor precisión y minimizando las fuentes de error con una recabación de un gran número de datos (lo cual ayuda a ir reduciendo el error aleatorio debido a causas fuera del control del experimentador) se llega a un valor más preciso de 1.60•10-19 coulombs para la carga del electrón, que es el valor aceptado hoy en día.
Este problema destaca que, antes de intentar ajustar un conjunto de datos experimentales a una fórmula, es importante estudiar detenidamente la gráfica de los datos para ver si no estamos omitiendo algo sumamente importante que nos están diciendo los datos. Tal vez ni siquiera resulte de importancia o de utilidad alguna el tratar de obtener una fórmula ajustada a los datos bajo tales condiciones.
